
Frank G. Halasz
Xerox PARC 3333 Coyote Hill Rd. Palo Alto, CA 94304 halasz@xerox.com
Mayer Schwartz
Tektronix Labs P.O. Box 500, MS 50-662 Beaverton, OR 97077 mayers@tekchips.labs.tek.com
Presented at the NIST Hypertext Standardization Workshop, Gaithersburg, MD, January 16-18, 1990
Abstract
This paper presents the Dexter hypertext reference model. The Dexter model is an attempt to capture, both formally and informally, the important abstractions found in a wide range of existing and future hypertext systems. The goal of the model is to provide a principled basis for comparing systems as well as for developing interchange and interoperability standards. The model is divided into three layers. The storage layer describes the network of nodes and links that is the essence of hypertext. The runtime layer describes mechanisms supporting the user’s interaction with the hypertext. The within-component layer covers the content and structures within hypertext nodes. The focus of the model is on the storage layer as well as on the mechanisms of anchoring and presentation specification that form the interfaces between the storage layer and the within-component and runtime layers, respectively. The model is formalized in the specification language Z [Spiv89], a specification language based on set theory. The paper briefly discusses the issues involved in comparing the characteristics of existing systems against the model.
Introduction
What do hypertext1 systems such as NoteCards [Hala88], Neptune [Deli86a], KMS [Aksc88a], Intermedia [Yank88a] and Augment [Enge84a] have in common? How do they differ? In what way do these systems differ from related classes of systems such as multimedia database systems. At a very abstract level, each of these hypertext systems provides its users with the ability to create, manipulate, and/or examine a network of information-containing nodes interconnected by relational links. Yet these systems differ markedly in the specific data models and sets of functionality that they provide to their users. Augment, Intermedia, NoteCards, and Neptune, for example, all provide their users with a universe of arbitrary-length documents. KMS and Hypercard, in contrast, are built around a model of a fixed-size canvas onto which items such as text and graphics can be placed. Given these two radically different designs, is there anything common between these systems in their notions of hypertext nodes?
In an attempt to provide a principled basis for answering these questions, this paper presents the Dexter hypertext reference model. The model provides a standard hypertext terminology coupled with a formal model of the important abstractions commonly found in a wide range of hypertext systems. Thus, the Dexter model serves as a standard against which to compare and contrast the characteristics and functionality of various hypertext (and non-hypertext) systems. The Dexter model also serves as a principled basis on which to develop standards for interoperability and interchange among hypertext systems.
The Dexter reference model described in this paper was initiated as the result of two small workshops on hypertext. The first workshop was held in October, 1988 at the Dexter Inn in New Hampshire. Hence the name of the model. The workshops had representatives from many of the major existing hypertext systems2 . A large part of the discussion at these workshops was the elicitation of the abstractions common to the major hypertext systems. The Dexter model is an attempt to capture, fill-out, and formalize the results of these discussions.
Another important focus of the workshops was an attempt to find a common terminology for the hypertext field. This turned out to be an extremely difficult task, especially so in the absence of an understanding of the common (and differing) abstractions among the various systems. The term "node" turned out to be especially difficult given the extreme variation in the use of the term across the various systems. By providing a well-defined set of named abstractions, the Dexter model provides a solution to the hypertext terminology problem. It does so, however, at some cost. In order to avoid confusion, the model does not use contentious terms such as "node", prefering neutral terms such as "component" for the abstraction in the model.
In the present paper, the Dexter model is formulated in Z [Spiv89], a formal specification language based on typed set theory. The use of Z provides a rigorous basis for defining the necessary abstractions and for discussing their use and interrelationships. Although an understanding of the Z language is a prerequisite for fully understanding the details of the Dexter model as described in this paper, the paper attempts to provide a complete description of the model in the prose accompanying the formal specification. Readers unfamiliar with Z should be able to gain a full, if not precisely detailed, understanding of the model.
This paper also refers in passing to architectural concepts found in a number of existing hypertext systems including Augment [Enge84a], Concordia/Document Examiner [Walk88a], Hypercard [Good87], Hyperties [Shne89d], IGD [Fein82], Intermedia [Yank88a], KMS [Aksc88a], Neptune/HAM [Deli86a], NoteCards [Hala88], the Sun Link Service [Pear89], and Textnet [Trig86a]. The reader is assumed to be familiar with the general characteristics and functionality of these systems. Appropriate background material on these systems can be found in Conklin [Conk87a] and in the proceedings of the Hypertext 87 [HT87] and Hypertext 89 [HT89] conferences.
This paper is divided in 4 main sections. The first section provides a brief discursive overview of the entire model. The second section describes the storage layer of the model, both formally and informally. The third section describes the runtime layer of the model in a similar manner. The final section discusses issues involved in comparing existing systems against the model.
An Overview of the Model
The Dexter model divides a hypertext system into three layers, the runtime layer, the storage layer and the within-component layer, as illustrated in Figure 1. The main focus of the model is on the storage layer, which models the basic node/link network structure that is the essence of hypertext. The storage layer describes a ‘database’ that is composed of a hierarchy of data-containing ‘‘components’’ which are interconnected by relational ‘‘links’’. Components correspond to what is typically thought of as nodes in a hypertext network: cards in NoteCards and HyperCard, frames in KMS, documents in Augment and Intermedia, or articles in Hyperties.
Components contain the chunks of text, graphics, images, animations, etc. that form the basic content in the hypertext network
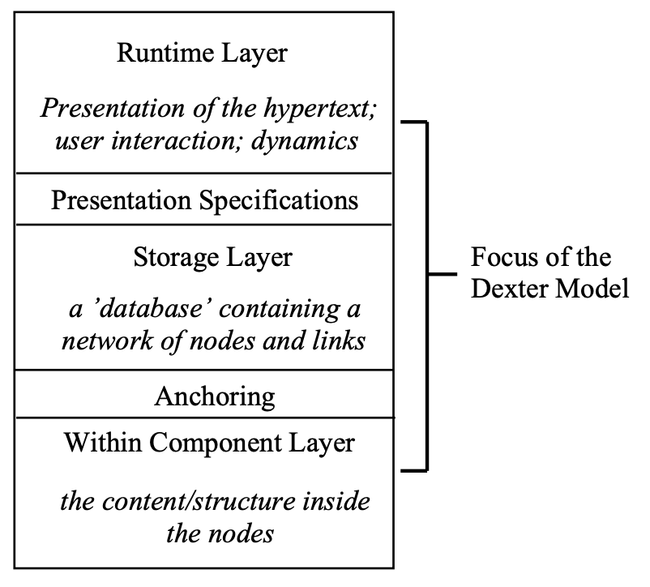
The storage layer focuses on the mechanisms by which the components and links are ‘‘glued together’’ to form hypertext networks. The components are treated in this layer as generic containers of data. No attempt is made to model any structure within the container. Thus, the storage layer makes no differentiation between text components and graphics components. Nor does it provide any mechanisms for dealing with the well-defined structure inherent within a structured document (e.g., an ODA document) component.
In contrast, the within-component layer of the model is specifically concerned with the contents and structure within the components of the hypertext network. This layer is purposefully not elaborated within the Dexter model. The range of possible content/structure that can be included in a component is open-ended. Text, graphics, animations, simulations, images, and many more types of data have been used as components in existing hypertext systems. It would be folly to attempt a generic model covering all of these data types. Instead, the Dexter model treats within-component structure as being outside of the hypertext model per se. It is assumed that other reference models designed specifically to model the structure of particular applications, documents, or data types (ODA, IGES, etc) will be used in conjunction with the Dexter model to capture the entirety of the hypertext, including the with-component content and structure.
An extremely critical piece of the Dexter model, however, is the interface between the hypertext network and the within-component content and structure. The hypertext system requires a mechanism for addressing (refering to) locations or items within the content of an individual component. In the Dexter model, this mechanism is know as anchoring. The anchoring mechanism is necessary, for example, to support span-to-span links such as are found in Intermedia. In Intermedia, the components are complete structured documents. Links are possible not only between documents, but between spans of characters within one document and spans of characters within another document. Anchors are a mechanism that provides this functionality while maintaining a clean separation between the storage and within-component layers.
The storage and within-component layers treat hypertext as an essentially passive data structure. Hypertext systems, however, go far beyond this in the sense that they provide tools for the user to access, view, and manipulate the network structure. This functionality is captured by the runtime layer of the model. As in the case of within-component structure, the range of possible tools for accessing, viewing, and manipulating a hypertext networks is far too broad and too diverse to allow a simple, generic model. Hence the Dexter model provides only a bare-bones model of the mechanism for presenting a hypertext to the user for viewing and editing. This presentation mechanism captures the essentials of the dynamic, interactional aspects of hypertext systems, but it does not attempt to cover the details of user interaction with the hypertext.
As in the case of anchoring, a critical aspect of the Dexter model is the interface between the storage layer and the runtime layer. In the Dexter model this is accomplished using the notion of presentation specifications. Presentation specifications are a mechanism by which information about how a component/network is to be presented to the user can be encoded into the hypertext network at the storage layer. Thus, the way in which a component is presented to the user can be a function not only of the specific hypertext tool that is doing the presentation (i.e., the specific runtime layer), but can also be a property of the component itself and/or of the access path (link) taken to that component.
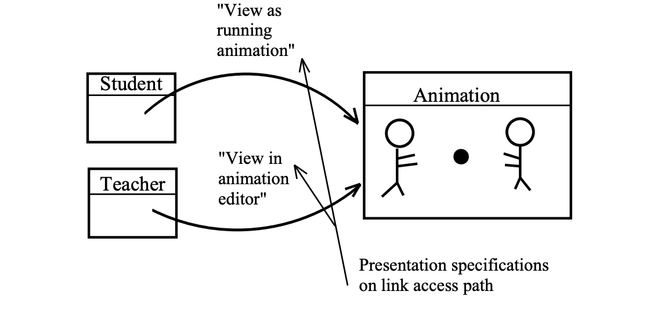
path (i.e., links) as well as on the components themselves.
Figure 2 illustrates the importance of the presentation specifications mechanism. In this figure, there is an animation component taken from a computer-based training hypertext. This animation component can be accessed from two other components, a ‘‘teacher’’ component and a ‘‘student’’ component. When following the link from the student component, the animation should be brought up as a running animation. In contast, when coming from the teacher component, the animation should be brought up in editing mode ready to be altered. In order to separate these two cases, the runtime layer needs to access presentation information encoded into the links in the network. Presentation specifications are a generic way of doing just this. Like anchoring, it is an interface that allows the storage layer to communicate in generic way with the runtime layer without violating the separation between the two layers.
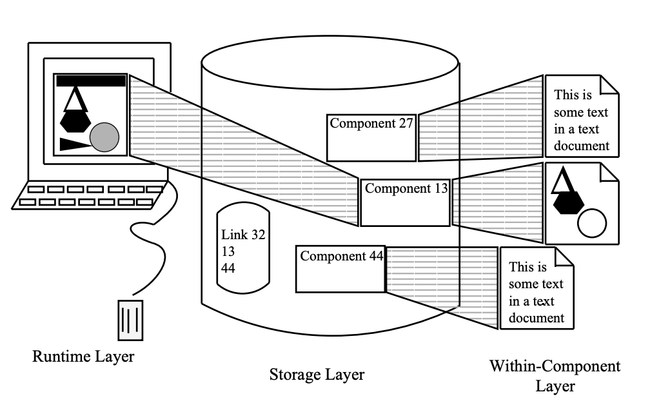
Figure 3 attempts to give a flavor of the various layers of the Dexter model as they are embedded within an typical hypertext system. The figure depicts a 3 node/1 link hypertext network. The storage layer contains four entities: the three components (i.e., nodes) and the link. The actual contents (text and graphics) for the components are located to the right of the storage layer in the within-components layer. In the runtime layer, the single graphics component is being presented to the user. The link emanating from this node is marked by an arrowhead located near the bottom of the node’s window on the computer screen.
another composite is restricted to be a direct-acyclic graph (DAG), i.e., no composite may contain itself either directly or indirectly. Composite components are relative rare in the current generation of hypertext systems. One exception is the Augment system where a document is a tree-structured composition of atomic components called statements.
Every component has a globally unique identity which is captured by its unique identifier (UID). UIDs are primitive in the model, but they are assumed to be uniquely assigned to components across the entire universe of discourse (not just within the context of a single hypertext). The accessor function of the hypertext is responsible for ‘‘accessing’’ a component given its UID, i.e., for mapping a UID into the component ‘‘assigned’’ that UID.
UIDs provide a guaranteed mechanism for addressing any component in a hypertext. But the use of UIDs as a basic addressing mechanism in hypertext may be too restrictive. For example, it is possible in the Augment system to create a link to ‘‘the statement containing the word ‘pollywog’’’. The statement specified by this link may not exist or it may change over time as documents are edited. Therefore, the link cannot rely on a specific statement UID to address the target statement. Rather, when the link is followed, the specification must be ‘‘resolved’’ to a UID (if possible), which then can be used to access the correct component.
This kind of indirect addressing is supported in the storage layer using component specifications together with the resolver function. The resolver function is responsible for ‘‘resolving’’ a component specification into a UID, which can then be fed to the accessor function to retrieve the specified component. Note, however, that the resolver function is only a partial function. A given specification may not be resolvable into a UID, i.e., the component being specified may not exist. However, it is the case that for every component there is at least one specification that will resolve to the UID for that component. In particular, the UID itself may be used as a specifier, in which case the resolver function is the identity function.
Implementing span-to-span links (e.g., in Intermedia) requires more than simply specifying entire components. Span-to-span linking depends on a mechanism for specifying substructure within components. But in order to preserve the boundary between the hypertext network per se and the content/structure within the components, this mechanism cannot depend in any way on knowledge about the internal structure of (atomic) components. In the Dexter model, this is accomplished by an indirect addressing entity called an anchor. An anchor has two parts: an anchor id and an anchor value. The anchor value is an arbitrary value that specifies some location, region, item, or substructure within a component. This anchor value is interpretable only by the applications responsible for handling the content/structure of the component. It is primitive and unrestricted from the viewpoint of the storage layer. The anchor id is an identifier which uniquely identifies its anchor within the scope of its component. Anchors can therefore be uniquely identified across the whole universe by a component UID, anchor id pair.
Do you like what you are reading? Subscribe to receive updates.
Unsubscribe anytime